



Est-ce que Taylor Swift chante en playback dans sa tournée ?
Des analyses d’enregistrements live tendent à le montrer, alors j’ai sorti mon python pour essayer d’y voir clair !


Il y a quelques semaines, le guitariste et vidéaste Fil de la chaîne Wings of Pegasus a sorti une vidéo accusant Taylor Swift de chanter en playback lors de sa dernière tournée The Eras. A l’appui de ses dires, une comparaison de vidéos prises dans différents concerts (Los Angeles, Liverpool, Tokyo, Lisbonne…) et qui montrent des similarités troublantes dans la voix de la chanteuse. L’auteur ne se contente pas d’une écoute subjective, mais isole la piste de voix et la soumet à un analyseur de fréquence pour montrer que certaines variations de hauteur se produisent de façon parfaitement synchrones, même sur des concerts différents.
Ci-dessous une capture montrant par exemple la comparaison de deux lignes vocales issues des concerts de Los Angeles (en bas) et Tokyo (en haut)
Et ci-dessous la même comparaison entre Los Angeles (en bas) et Lisbonne (en haut).
A première vue, je dois dire que la démonstration est plutôt convaincante. Il y a quelques jours, le pianiste Étienne Guéreau de la chaîne Piano Jazz Concept a reproduit l’analyse de façon indépendante, en utilisant toutefois les mêmes outils que Wings of Pegasus.
Si on fait l’avocat du diable, on pourrait argumenter que ce ne sont peut-être que de coïncidences qui ont été “cherry-pickées”. Ou bien suggérer qu’il s’agit d’artefacts introduits par le traitement (les logiciels utilisés sont des applications commerciales, et peuvent donc avoir tendance à cacher les limites et défauts de leur fonctionnement.) Sachant que ceux-ci opèrent sur une voix qui est déjà manifestement auto-tunée et avec beaucoup d’effets.
J’ai donc, à titre d’exercice, décidé de voir si je pouvais retrouver des résultats similaires par une méthode complètement indépendante, en utilisant un code reproductible et des méthodes de traitement du signal. Voici le résultat de mon investigation !
Commençons par préciser ce que l’on cherche à faire : je ne cherche pas à démontrer qu’il y a de l’auto-tune (ou équivalent), c’est évident qu’il y en a, vu comme les notes tombent juste. Je ne cherche pas non plus à démontrer que c’est “le disque d’origine” qui est joué. Comme Wings of Pegasus, je cherche à voir si ce qu’on entend est une piste vocale pré-enregistrée, et jouée à l’identique pendant les différents concerts…ou bien si l’on entend vraiment l’artiste en direct.
Autre précision : je ne fais pas partie de l’audience de Taylor Swift, je n’ai donc aucun affect là-dedans, ni aucune opinion sur le fait de savoir si c’est grave ou pas si elle fait du playback en concert sur tout ou partie de ses morceaux.
Les sources
La démonstration de Wings of Pegasus utilise la chanson Style de Taylor Swift, et même plus précisément les 30 premières secondes de celle-ci. Je vais utiliser les mêmes vidéos que lui : la vidéo officielle de trailer (issue du concert de Los Angeles), le concert de Lisbonne et celui de Tokyo, filmés par des personnes du public (la vidéo de Liverpool a malheureusement disparu). En bon scientifique, j’ai aussi décidé d’introduire un “groupe de contrôle” : une vidéo de la même chanson mais issue d’une tournée précédente, la tournée 1989 qui a eu lieu il y a une dizaine d’années (dans la suite, quand je parle de la vidéo de 1989, je parle donc d’une vidéo de 2015…vous suivez ?) On peut à l’oreille sur cette autre version entendre qu’elle est légèrement différente dans le phrasé de l’artiste.
J’ai d’abord synchronisé les morceaux, ce qui ne pose pas de difficulté puisque ceux-ci sont joués avec une boite à rythme au même tempo sur tous les concerts. Nous pourrons donc comparer les hauteurs (pitchs) mais aussi les timings des phrases sans avoir à essayer de superposer à la main.
Voici les paroles des phrases que nous allons analyser, il s’agit des deux premières de la chanson :
Midnight
You come and pick me up, no headlights
Long drive
Could end in burning flames or paradise
Les notes chantées sur ce passage se promènent entre le D4 (environ 294 Hz), le E4 (330Hz) et le F#4 (370 Hz).
Un peu de traitement du signal
Fondamentalement ce que l’on cherche à faire, c’est une analyse temps/fréquence. On veut analyser l’évolution dans le temps de la hauteur des notes. Deux difficultés vont se poser à nous.
La première c’est que le signal de départ est extrêmement complexe : on a plusieurs instruments, de l’écho et de la reverb, et surtout le public qui ajoute un brouhaha et qui parfois chante par dessus l’artiste de façon audible (et souvent fausse !)
La seconde, c’est que faire une analyse temps-fréquence, c’est nécessairement une affaire de compromis. On ne peut pas avoir à la fois une très bonne résolution en temps ET en fréquence, c’est une limite mathématique (qu’on peut comparer au principe d’incertitude d’Heisenberg !). Les courbes continues présentées par Wings Of Pegasus peuvent donner l’impression contraire, en faisant croire qu’on peut suivre de façon très précise le pitch au cours du temps : ça n’est pas le cas !
Pour se faire une première idée de ces difficultés, on peut s’amuser à tracer des spectrogrammes, c’est-à-dire une représentation de l’intensité sonore par fréquence en fonction du temps. Je le fais ici sur quelques secondes correspondant à la phrase “Midnight. You come and pick me up, no headlights”, et pour les 4 vidéos
Vous voyez que c’est un beau bordel ! Il y a plein de fréquences parasites, mais on devine tout de même les lignes vocales de Taylor Swift, notamment “Mid-night” à la première seconde, et “Head-light” entre 5 et 6 secondes. On trouve les fondamentales autour de 300Hz et les premières harmoniques vers 600 Hz. Mais vous voyez que ça n’est pas comme si une fine ligne parfaitement résolue se dessinait ! On peut, si on le souhaite, augmenter la résolution spectrale (en fréquence), mais au prix d’une perte de résolution temporelle, et réciproquement.
Ici j’ai utilisé une fenêtre de 2048 échantillons pour une fréquence de 22.05 kHz.

Difficile sur ces simples spectrogrammes d’espérer y voir clair. Il va donc falloir faire plus subtil et passer par de la séparation de sources.
Isoler la voix
Pour ça j’ai utilisé l’algorithme spleeter et notamment son modèle 2stems qui permet de séparer la voix de l’accompagnement.

Ca marche mais ça n’est pas parfait, notamment sur les prises depuis le public ou parfois la voix de Taylor Swift n’est pas assez forte pour émerger à la séparation. Malgré tout il y a plusieurs phrases exploitables. Voici une estimation du volume RMS des 30 premières secondes de chaque source
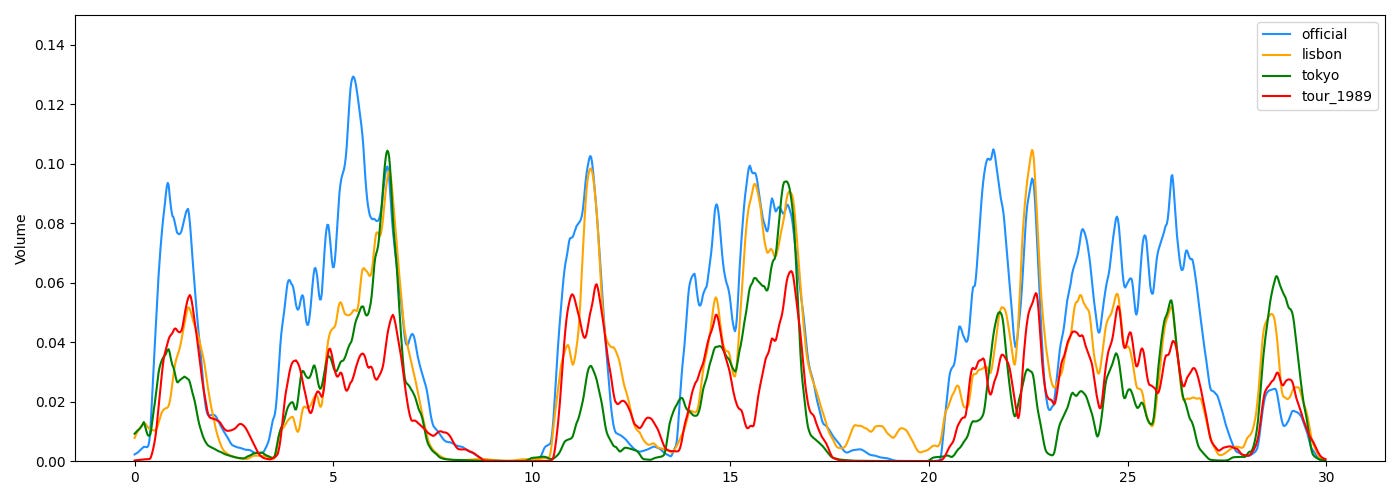
La piste officielle est la plus propre, puisqu’elle n’est pas capturée depuis le public. Mais on a quand même plusieurs passages où à la fois les pistes de Tokyo et Lisbonne sont bien capturées (et à l’écoute c’est raisonnable).
Tracer l’évolution du pitch
Pour faire un peu mieux que le spectrogramme que j’ai présenté au début, on peut utiliser des algorithmes dédiés de détection du pitch. Mais les mêmes restrictions s’appliquent ! On ne peut pas être parfaitement résolu à la fois en temps et en fréquence.
Voici comment cela se passe : on estime le pitch sur une fenêtre et on la fait glisser pour tracer l’évolution temporelle. Prenons l’exemple d’une taille de fenêtre de 2048 échantillons pour mon signal à 22050 Hz, cela correspond à une taille de fenêtre d’environ 100 millisecondes. Donc en principe je ne peux avoir qu’un point toutes les 100 millisecondes ! On peut artificiellement abaisser cette valeur en faisant glisser la fenêtre de moins que sa taille, typiquement 1/4 de sa taille. Cela signifie qu’on aura 4 fois plus de points, mais que d’un point à l’autre, ce sont les 3/4 des données qui seront en commun. Cela produit donc un signal artificiellement lissé. Ca n’est pas nécessairement un problème, mais il faut en être conscient.
Pour ma part, j’ai décidé de partir sur une taille de fenêtre de 2048 et un glissement de 50%, donc un point toutes les 50ms. J’ai utilisé l’algorithme YIN.
Et voici ce qu’on obtient sur les 13 premières secondes, correspondant aux deux premières phrases.
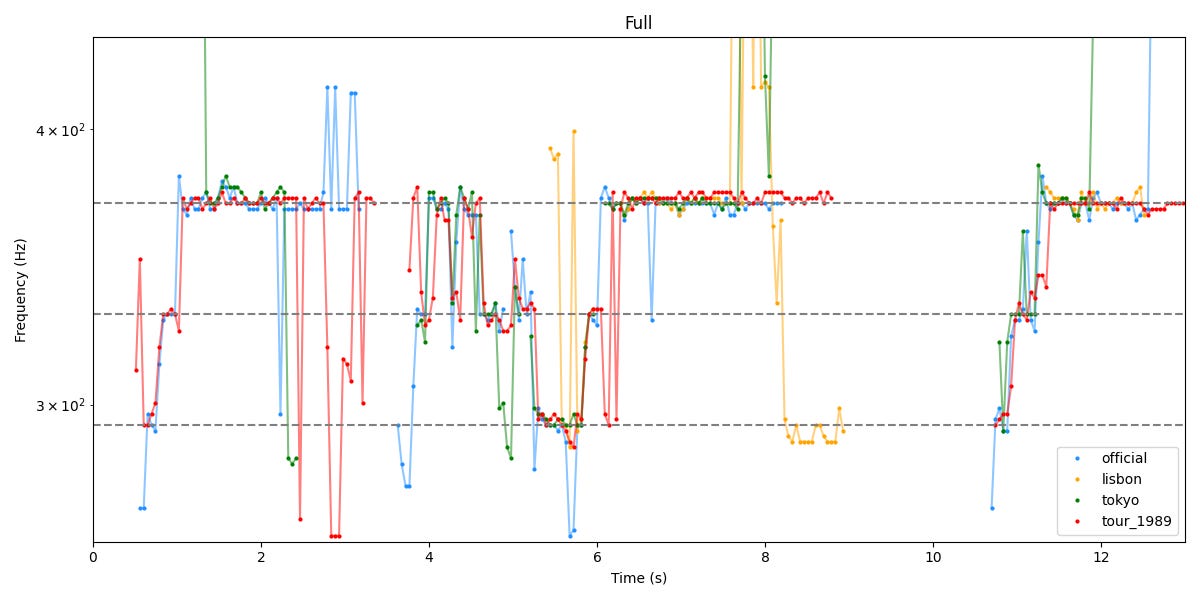
Les lignes pointillées correspondent aux fréquences des notes de la mélodie (D4,E4,F#4). On voit que c’est pas nickel ! A de nombreux endroits, même dans la vidéo officielle qui est propre, l’estimation de pitch semble aux fraises. Il est intéressant de se concentrer sur les phrases où il y a le plus de signal clair.
Sur le premier mot, “Midnight”, on n’a pas vraiment de signal des vidéos de Lisbonne et Tokyo à part sur la note tenue.
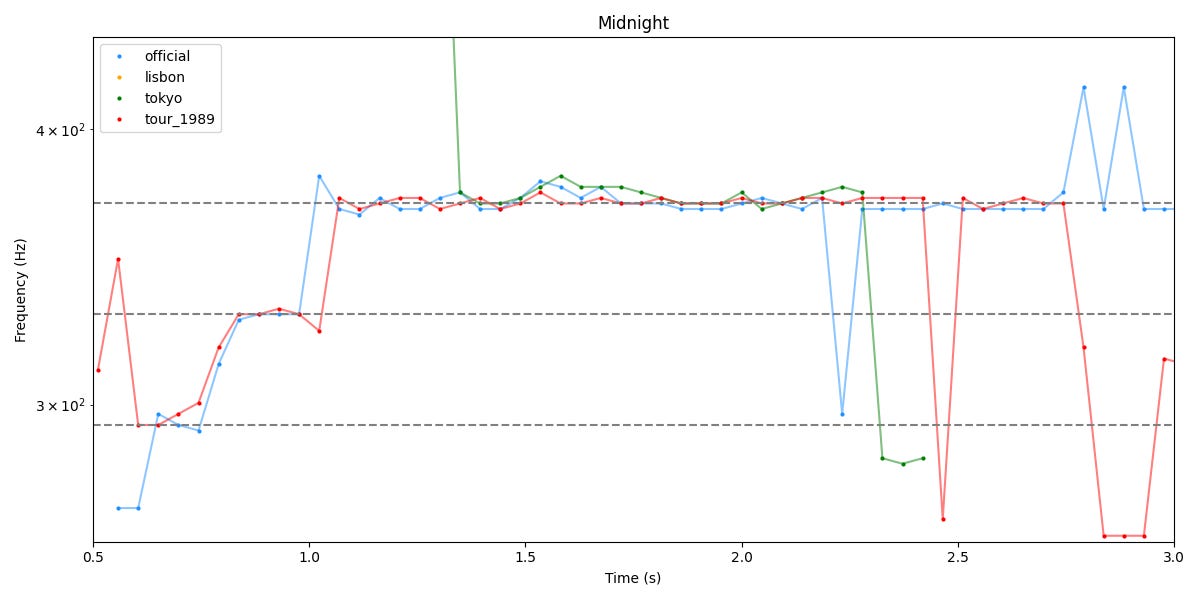
On voit donc l’effet de l’auto-tune. On remarque aussi que sur la vidéo officielle et celle de la tournée “1989”, la montée du début est remarquablement synchronisée…mais là-aussi peut-être est-ce simplement l’auto-tune qui fait son job ?
Dans la phrase suivante, on a une belle similarité entre Tokyo et l’officielle, pas de signal de Lisbonne, et pour le coup 1989 est différente :
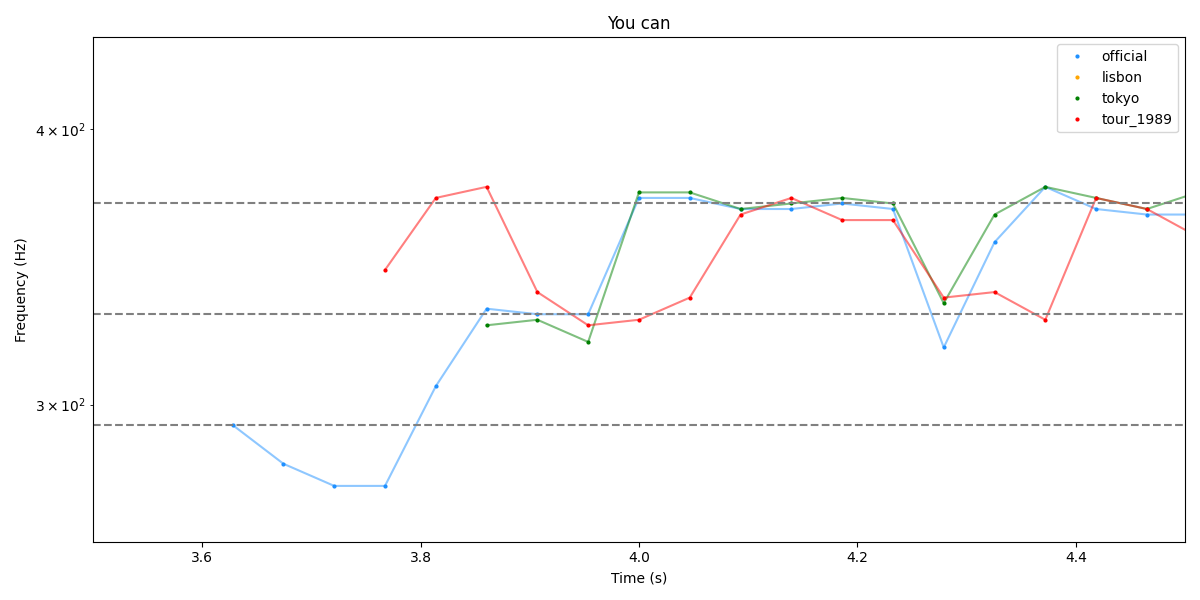
Passons à “No head-light” autour de 6 secondes, que Wings of Pegasus avait aussi regardé
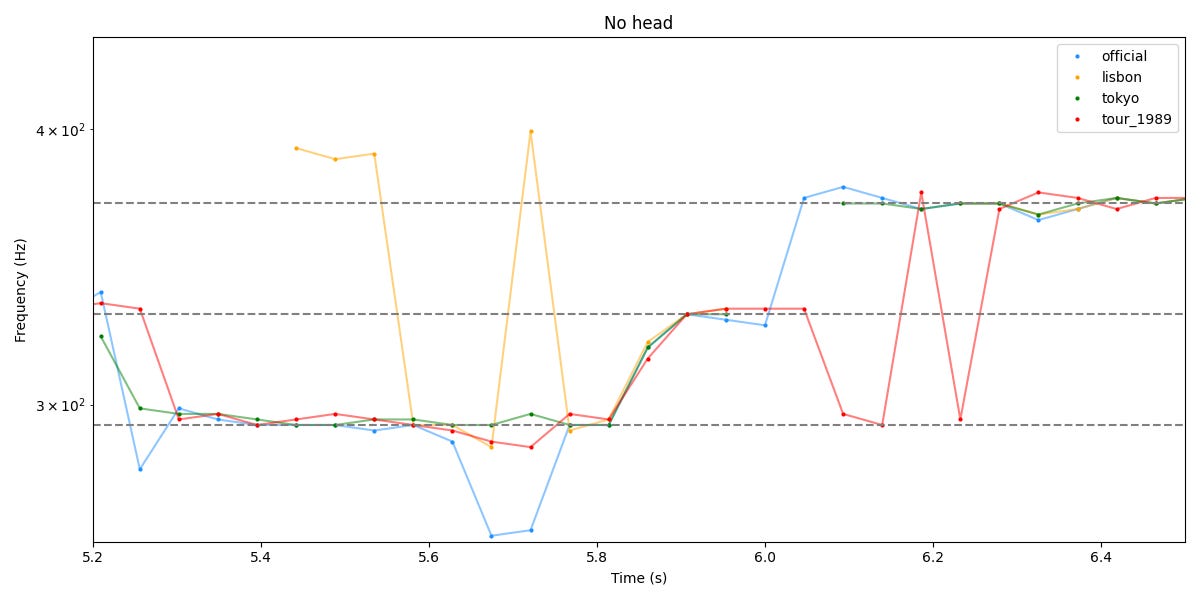
Idem, entre 5.8 et 6.0, la montée semble parfaitement synchrone sur les 4 pistes, mais à nouveau c’est peut-être l’autotune qui fait son job de la même façon. La preuve, même la piste de la tournée précédente (en rouge) suit parfaitement les 3 autres ! Les oscillations légères semblent aussi synchro sur la fin.
Passons au segment suivant “Long drive”, celui sur le lequel Wings of Pegasus semble le plus convaincant (et dont sont issues les captures que j’ai mises au début de ce billet)
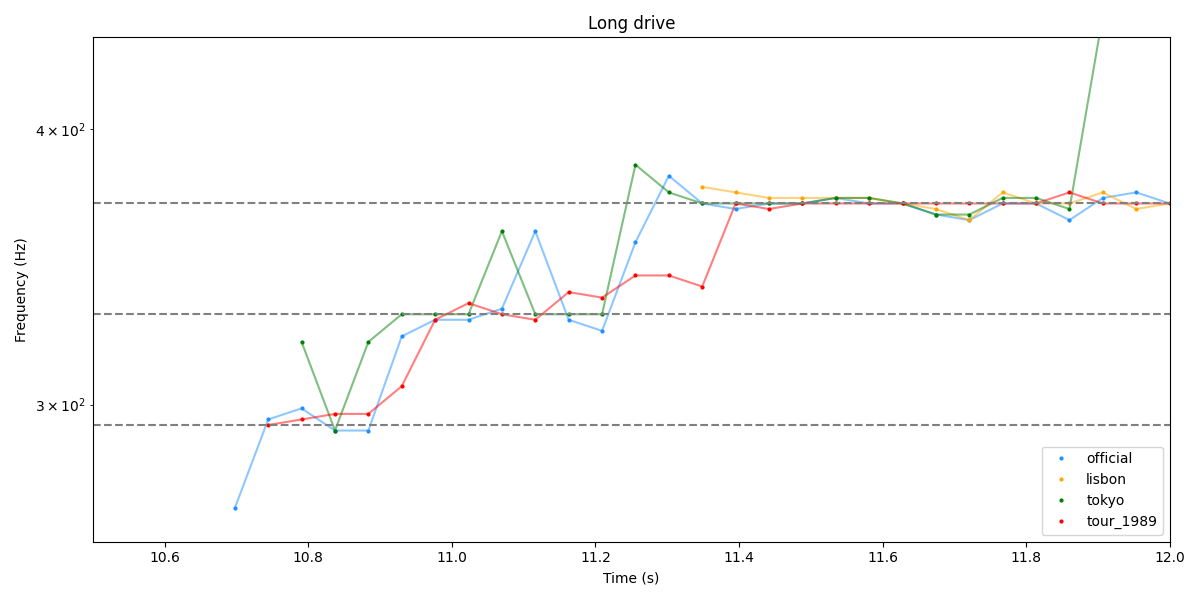
On note à nouveau des similarités (bien qu’un peu décalées ?) dans la montée, et des oscillations synchrones sur la note tenue, notamment autour de 11.6-11.8.
Pour finir, voici les 10 secondes suivantes du morceau “Fade into view, oh. It's been a while since I have even heard from you”
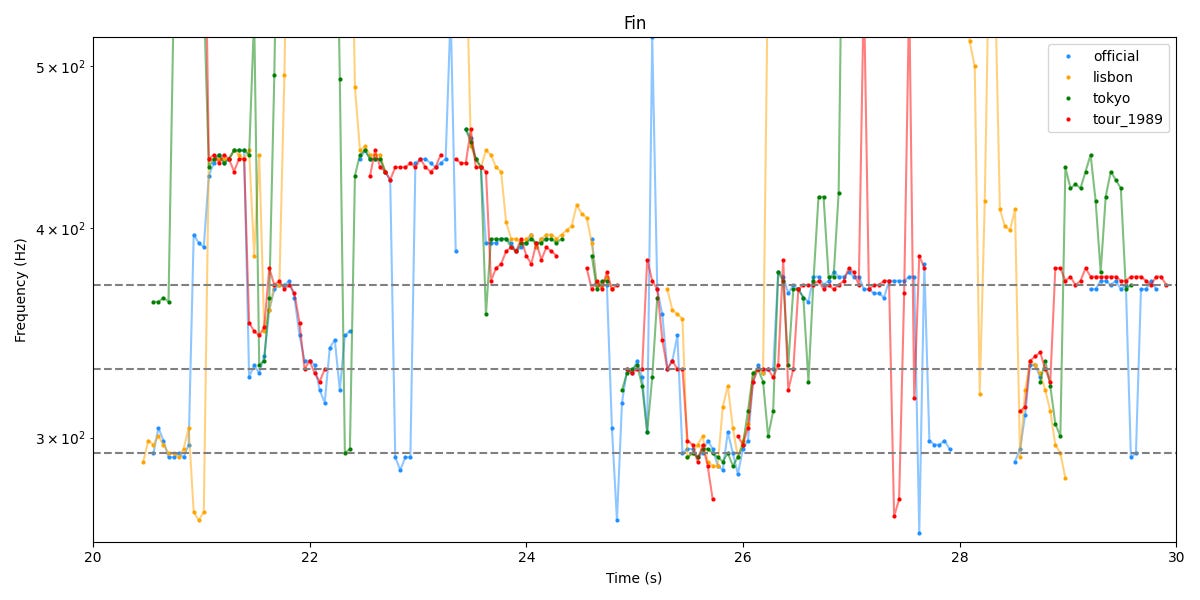
A nouveau des similarités troublantes, entre les 3 vidéos de la tournée The Eras, mais aussi par moment avec celle de la tournée 1989 (mais qui a d’autres endroits semble assez différente).
Le bénéfice du doute ?
Tout d’abord, il est rassurant de voir que, même en utilisant des outils (a priori) complètement différents, je retrouve en gros les similarités déjà relevées par Wings of Pegasus, et aux mêmes endroits.
Mais il y a deux éléments (reliés) qui m’incitent tout de même à la prudence : le rôle de l’auto-tune et les similarités que je relève aussi parfois avec la version de la tournée 1989 (qui date pourtant d’il y a presque 10 ans !) L’effet de l’autotune pourrait-il être à ce point qu’il produit une telle uniformisation ? Et si on imagine qu’en plus, l’autotune est synchronisé sur le tempo : le rôle de l’artiste se limiterait à chanter à peu près la bonne note à peu près au bon moment ? Ou bien peut-on imaginer qu’en concert on ait à la fois la vraie voix de l’artiste et une piste de backing ?
Ajoutons à cela l’effet bien connu des “comparaisons multiples” : si on cherche dans suffisamment de données, on finit toujours par trouver des corrélations. Il faudrait probablement faire l’exercice sur plus de morceaux, plutôt que celui-là seul.
En conclusion et à l’issue de cette analyse, j’ai envie d’accorder un tout petit peu plus le bénéfice du doute à Taylor Swift. Tout en se souvenant que dans tous les cas, je n’ai analysé là que quelques secondes d’un seul morceau. On peut aussi volontiers imaginer que le playback soit utilisé partiellement suivant les morceaux pour ménager la voix de l’artiste. Je n’ai pas l’intention d’en faire beaucoup plus, c’était surtout pour moi un exercice pour me refaire la main sur les algorithmes de traitement du signal. Mais si vous le souhaitez, je mets mon code en accès libre, et peut-être qu’avec de meilleures méthodes (ou des vidéos supplémentaires ?) il sera possible de faire un peu mieux. N’hésitez pas si vous souhaitez poursuivre l’analyse !
Bonjour, David. Premièrement, j'en profite :, un grand merci pour votre contenu depuis toutes ces années !
Contrairement à votre question, l'autotune peut agir à la volée, pas besoin d'un enregistrement ou d'une analyse spectrale hyper détaillée en back-tracking pour le fonctionnement. C'est un peu le principe du vocoder, qui au lieu d'indiquer la note via un clavier, c'est un repérage "à la volée" comme avec un détecteur de tonalité pour l'accordage de guitare qui agit pour réaccorder la note entendue du signal de départ.
Tout cette histoire se joue au contraire, le diable étant dans les détails, entre un back-tracking de sécurité, on va dire, et la performance en direct. Etienne Guéreau prenait l'exemple de Céline Dion au J.O., avec la question de savoir où est la vérité originale, ce qui est un petit peu naïf dans le cadre de toute musique amplifiée, et de l'intervention en direct d'ingénieur du son, même si je comprends tout à fait l'intention plus politique que technique, finalement, de Guéreau à la base.
Bonjour. En effet, il est fort probable que, comme on dit dans le métier, on "ouvre un peu le micro" sur du playback, laissant un petite marge d'interprétation à l'artiste. Comme vous dites, David, cela peut changer suivant les chansons.